AMD Instinct MI300A Accelerators
Integrated CPU/GPU accelerated processing unit for high-performance computing, generative AI, and ML training.
Integrated CPU/GPU accelerated processing unit for high-performance computing, generative AI, and ML training.
Integrated CPU/GPU accelerated processing unit for high-performance computing, generative AI, and ML training.
AMD Instinct MI300A accelerated processing units (APUs) combine the power of AMD Instinct accelerators and AMD EPYC processors with shared memory to enable enhanced efficiency, flexibility, and programmability. They are designed to accelerate the convergence of AI and HPC, helping advance research and propel new discoveries.
228 CUs
228 GPU Compute Units24
24 “Zen 4” x86 CPU Cores128 GB
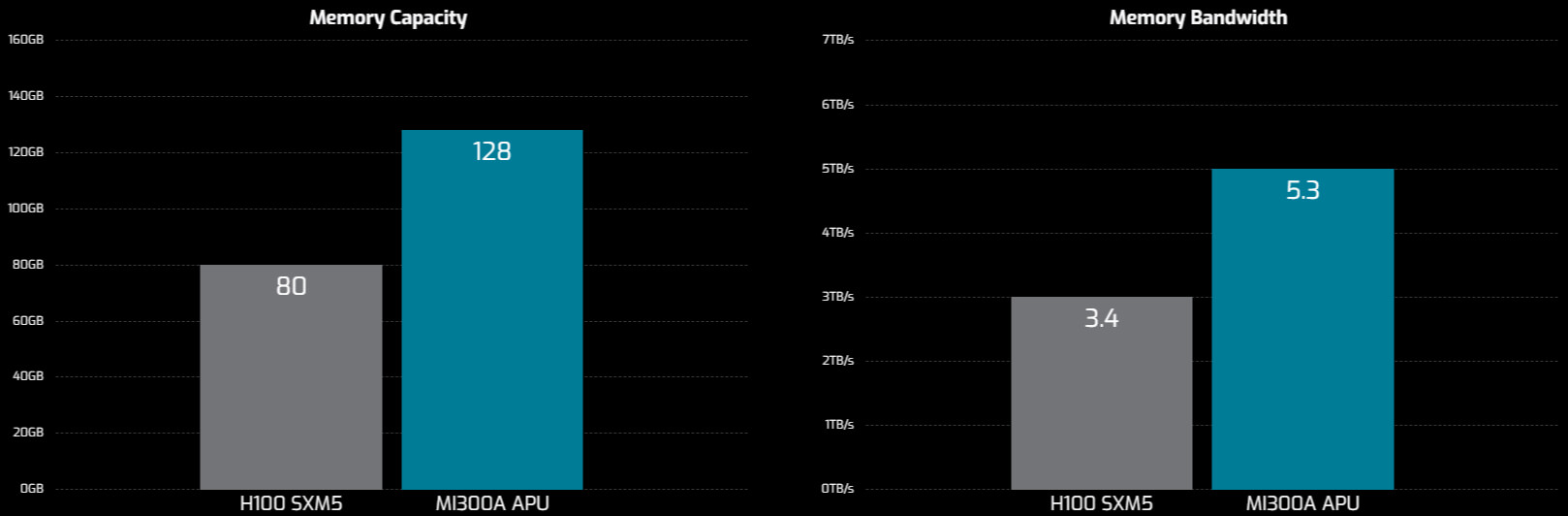
128 GB Unified HBM3 Memory5.3 TB/s
5.3 TB/s Peak Theoretical Memory BandwidthBased on next-generation AMD CDNA 3 architecture, the AMD Instinct MI300A accelerated processing unit (APU) is designed to deliver outstanding efficiency and performance for the most-demanding HPC and AI applications. The APU is built from the ground up to overcome the challenges that discrete GPUs present: performance bottlenecks from the narrow interfaces between CPU and GPU, burdensome programming overhead for managing data, and the need to refactor and recompile code for every GPU generation. The AMD Instinct MI300A integrates 24 AMD ‘Zen 4’ x86 CPU cores with 228 AMD CDNA 3 high-throughput GPU compute units, 128 GB of unified HBM3 memory that presents a single shared address space to CPU and GPU, all of which are interconnected into the coherent 4th Gen AMD Infinity architecture. Slated for next-generation supercomputers, this technology is available to enterprise data centers through platforms offered by our solution partners.

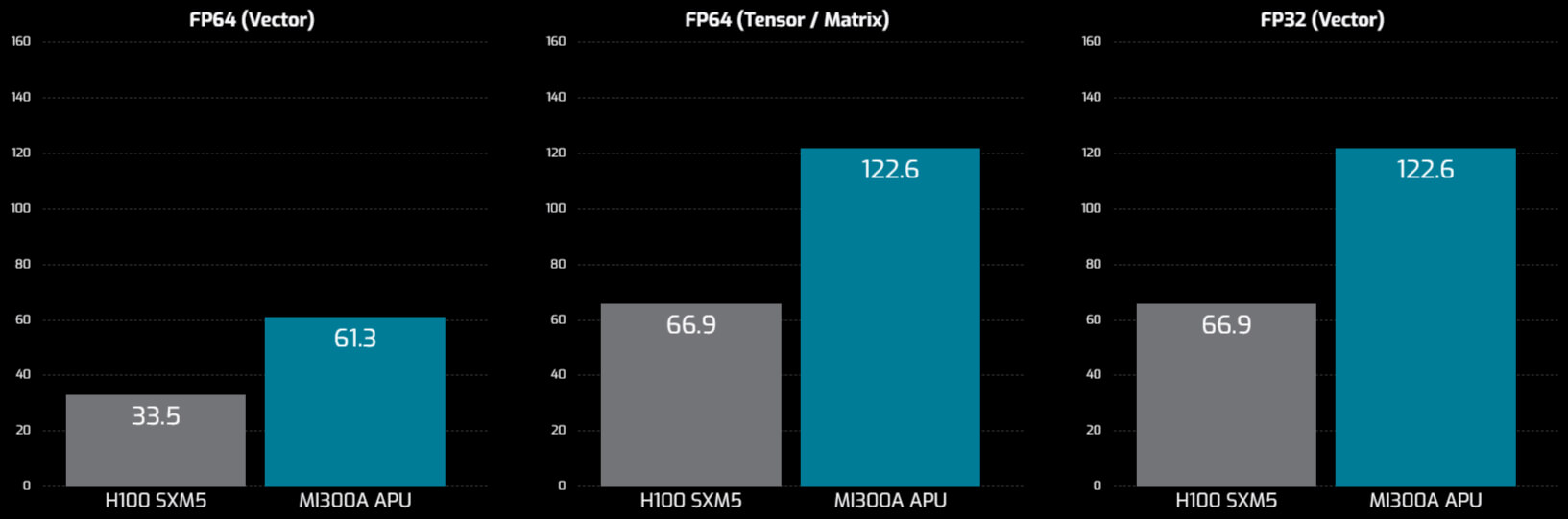
| FP64 vector | 61.3 |
| FP32 vector | 122.6 |
| FP64 matrix | 122.6 |
| FP32 matrix | 122.6 |
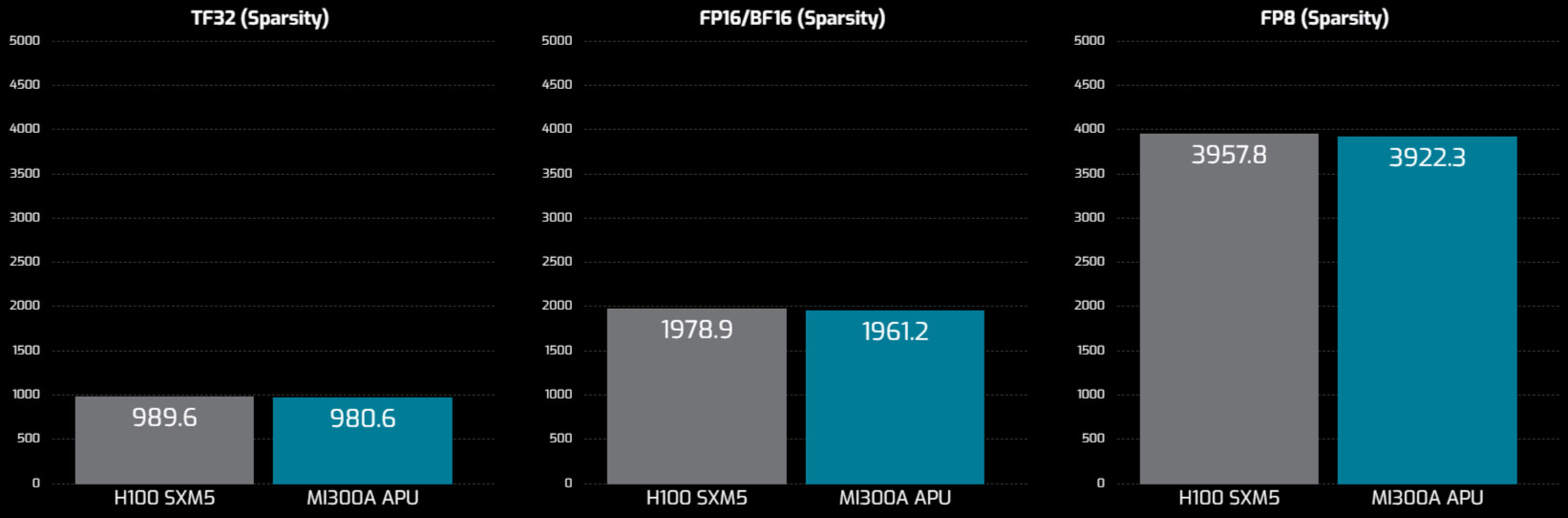
| TF32 matrix (TFLOPs) | 490.3 | *980.6 |
| FP16 (TFLOPs) | 980.6 | *1961.2 |
| BFLOAT16 (TFLOPs) | 980.6 | *1961.2 |
| INT8 (TOPS) | 1961.2 | *3922.3 |
| FP8 (TFLOPS) | 1961.2 | *3922.3 |
| Decoders1 | 3 groups for HEVC/H.265, AVC/H.264, V1, or AV1 |
| JPEG/MJPEG CODEC | 24 cores, 8 cores per group |
| Virtualization support | SR-IOV, up to 3 partitions |
| Form Factor | APU SH5 socket |
| Lithography | 5nm FinFET |
| Active Interposer Dies (AIDs) | 6nm FinFET |
| CPU Cores | 24 |
| Matrix Cores | 228 |
| Stream Processors | 912 |
| Peak Engine Clock | 2100 MHz |
| Memory Capacity | 128 GB HBM3 |
| Memory Bandwidth | 5.3 TB/s max. peak theoretical |
| Memory Interface | 8192 bits |
| Cache | 256 MB |
| Memory Clock | 5.2 GT/s |
| Scale-up Infinity Fabric™ Links | 4 x16 (128 GB/s) |
| Scale-out assignable PCIe® Gen 5 or Infinity Fabric Links | 4 x16 (128 GB/s) |
| Scale-out network bandwidth | 400 Gbps Ethernet or InfiniBand™ |
| RAS features | Full-chip ECC memory, page retirement, page avoidance |
| Maximum TDP | 550W (air & liquid cooling) 760W (liquid cooling) |
The AMD Instinct MI300A is built to accelerate the convergence of HPC and AI applications at scale.
To meet the increasing demands of AI applications, the APU is optimized for widely used data types including FP64, FP32, FP16, BF16, TF32, FP8, and INT8, including native hardware sparsity support for efficiently gathering data from sparse matrices. This helps save power and compute cycles while helping reduce memory use. By integrating ‘Zen 4’ CPU cores and GPU accelerators, you can achieve high efficiency by eliminating timeconsuming data copy operations, transparently managing CPU and GPU caches, offloading tasks easily between GPU and CPU, and efficient synchronization, all supported by the AMD ROCm 6 open software platform. Virtualized environments can be supported through SR-IOV to share resources with up to three partitions per APU.
The APU uses state-of-the-art die stacking and chiplet technology in a multi-chip architecture, enabling dense compute and high-bandwidth memory integration. This helps reduce data-movement overhead while enhancing power efficiency. Each device includes:
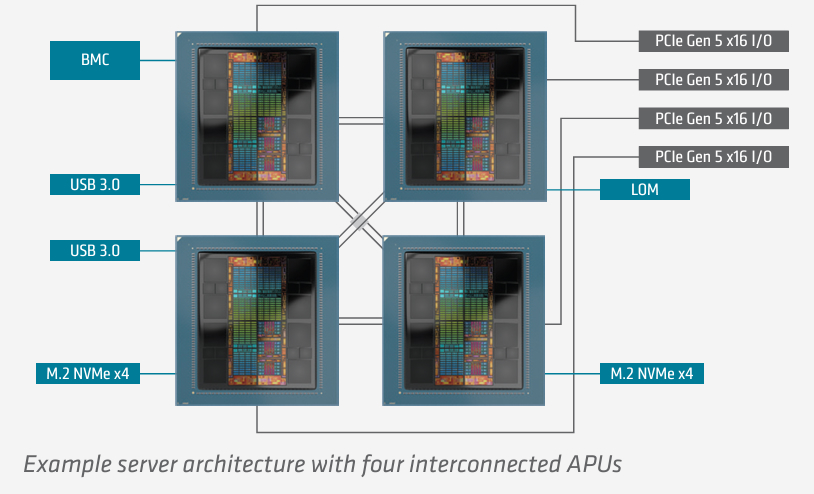
Each APU provides 1 TB/s of bidirectional connectivity through eight 128 GB/s AMD Infinity Fabric interfaces. Four interfaces are dedicated Infinity Fabric links, while four can be flexibly assigned to deliver either Infinity Fabric or PCIe Gen 5 connectivity. In a typical 4-APU configuration, six interfaces are dedicated to interGPU Infinity Fabric connectivity for a total of 384 GB/s of peer-to-peer connectivity per APU, with one interface assigned to support x16 PCIe® Gen 5 connectivity to external I/O devices. In addition, each MI300A includes two x4 interfaces to storage, such as M.2 boot drives, plus two USB Gen 2 or 3 interfaces.
Our Value
As a leading HPC provider, Aspen Systems offers a standardized build and package selection that follows HPC best practices. However, unlike some other HPC vendors, we also provide you the opportunity to customize your cluster hardware and software with options and capabilities tuned to your specific needs and your environment. This is a more complex process than simply providing you a “canned” cluster, which might or might not best fit your needs. Many customers value us for our flexibility and engineering expertise, coming back again and again for upgrades to existing clusters or new clusters which mirror their current optimized solutions. Other customers value our standard cluster configuration to serve their HPC computing needs and purchase that option from us repeatedly. Call an Aspen Systems sales engineer today if you wish to procure a custom-built cluster built to your specifications.
Aspen Systems typically ships clusters to our customers as complete turn-key solutions, including full remote testing by you before the cluster is shipped. All a customer will need to do is unpack the racks, roll them into place, connect power and networking, and begin computing. Of course, our involvement doesn’t end when the system is delivered.
With decades of experience in the high-performance computing industry, Aspen Systems is uniquely qualified to provide unparalleled systems, infrastructure, and management support tailored to your unique needs. Built to the highest quality, customized to your needs, and fully integrated, our clusters provide many years of trouble-free computing for customers all over the world. We can handle all aspects of your HPC needs, including facility design or upgrades, supplemental cooling, power management, remote access solutions, software optimization, and many additional managed services.
Aspen Systems offers industry-leading support options. Our Standard Service Package is free of charge to every customer. We offer additional support packages, such as our future-proofing Flex Service or our fully managed Total Service package, along with many additional Add-on services! With our On-site services, we can come to you to fully integrate your new cluster into your existing infrastructure or perform other upgrades and changes you require. We also offer standard and custom Training packages for your administrators and your end-users or even informal customized, one-on-one assistance.

As a leading HPC provider, Aspen Systems offers a standardized build and package selection that follows HPC best practices. However, unlike some other HPC vendors, we also provide you the opportunity to customize your cluster hardware and software with options and capabilities tuned to your specific needs and your environment. This is a more complex process than simply providing you a “canned” cluster, which might or might not best fit your needs. Many customers value us for our flexibility and engineering expertise, coming back again and again for upgrades to existing clusters or new clusters which mirror their current optimized solutions. Other customers value our standard cluster configuration to serve their HPC computing needs and purchase that option from us repeatedly. Call an Aspen Systems sales engineer today if you wish to procure a custom-built cluster built to your specifications.
Aspen Systems typically ships clusters to our customers as complete turn-key solutions, including full remote testing by you before the cluster is shipped. All a customer will need to do is unpack the racks, roll them into place, connect power and networking, and begin computing. Of course, our involvement doesn’t end when the system is delivered.
With decades of experience in the high-performance computing industry, Aspen Systems is uniquely qualified to provide unparalleled systems, infrastructure, and management support tailored to your unique needs. Built to the highest quality, customized to your needs, and fully integrated, our clusters provide many years of trouble-free computing for customers all over the world. We can handle all aspects of your HPC needs, including facility design or upgrades, supplemental cooling, power management, remote access solutions, software optimization, and many additional managed services.
Aspen Systems offers industry-leading support options. Our Standard Service Package is free of charge to every customer. We offer additional support packages, such as our future-proofing Flex Service or our fully managed Total Service package, along with many additional Add-on services! With our On-site services, we can come to you to fully integrate your new cluster into your existing infrastructure or perform other upgrades and changes you require. We also offer standard and custom Training packages for your administrators and your end-users or even informal customized, one-on-one assistance.
AMD MI300A
Whatever your workload, AMD ROCm software opens doors to new levels of freedom and accessibility. Proven to scale in some of the world’s largest supercomputers, ROCm software provides support for leading programing languages and frameworks for HPC and AI. With mature drivers, compilers and optimized libraries supporting AMD Instinct accelerators, ROCm provides an open environment that is ready to deploy when you are.
Some of the most popular HPC programing languages and frameworks are part of the ROCm software platform, including those to help parallelize operations across multiple GPUs and servers, handle memory hierarchies, and solve linear systems. Our GPU Accelerated Applications Catalog includes a vast set of platform-compatible HPC applications, including those in astrophysics, climate & weather, computational chemistry, computational fluid dynamics, earth science, genomics, geophysics, molecular dynamics, and physics. Many of these are available through the AMD Infinity Hub, ready to download and run on servers with AMD Instinct accelerators.
Support for the most popular AI & ML frameworks—PyTorch, TensorFlow, ONYX-RT, Triton and JAX—make it easy to adopt ROCm software for AI deployments on AMD Instinct accelerators. The ROCm software environment also enables a broad range of AI support for leading compilers, libraries and models making it fast and easy to deploy AMD based accelerated servers. The AMD ROCm Developer Hub provides easy access point to the latest ROCm drivers and compilers, ROCm documentation, and getting started training webinars, along with access to deployment guides and GPU software containers for AI, Machine Learning and HPC applications and frameworks.
The most common plug/receptacle types you will encounter in North America are:
 Cooling
CoolingTo figure out which size unit is best for your cooling needs: