NVIDIA® Grace CPUs
Designed from the ground-up to answer the humanity’s most challenging problems.
Designed from the ground-up to answer the humanity’s most challenging problems.
Designed from the ground-up to answer the humanity’s most challenging problems.

AI models are exploding in complexity and size as they enhance deep recommender systems containing tens of terabytes of data, improve conversational AI with hundreds of billions of parameters, and enable scientific discoveries. Scaling these massive models requires new architectures with fast access to a large pool of memory and a tight coupling of the CPU and GPU. The NVIDIA Grace CPU delivers high performance, power efficiency, and high-bandwidth connectivity that can be used in diverse configurations for different data center needs.
Exascale AI Performance—Unified Compute for Trillion-Parameter Workloads
The NVIDIA GB200 NVL72 is a groundbreaking rack-scale system engineered to accelerate the most demanding AI and high-performance computing (HPC) applications. Integrating 36 Grace CPUs and 72 Blackwell GPUs through fifth-generation NVLink™, it delivers up to 30× faster real-time inference for trillion-parameter large language models (LLMs) compared to previous-generation systems .
With a unified 72-GPU NVLink domain acting as a single massive GPU, the GB200 NVL72 offers 130 terabytes per second (TB/s) of low-latency GPU communication, enabling seamless scalability and efficiency for large-scale AI training and inference tasks .
Designed with energy efficiency in mind, its liquid-cooled architecture provides 25× greater performance per watt, reducing data center power consumption while maximizing computational throughput .
Key Advantages
Inference at Unmatched Scale
The NVIDIA GB200 NVL72 redefines large-scale AI infrastructure by interconnecting 36 Grace CPUs and 72 Blackwell GPUs within a fully integrated, rack-scale, liquid-cooled system. Operating as a unified 72-GPU NVLink™ domain, the NVL72 functions like a single, colossal GPU — delivering up to 30× faster inference for trillion-parameter large language models in real time.
At the heart of this innovation is the GB200 Grace Blackwell Superchip. By fusing two powerful Blackwell Tensor Core GPUs with a Grace CPU via ultra-high-bandwidth NVLink-C2C, each module delivers seamless memory coherence and accelerated compute performance — enabling enterprises to build and deploy next-gen AI models with unparalleled speed and efficiency.
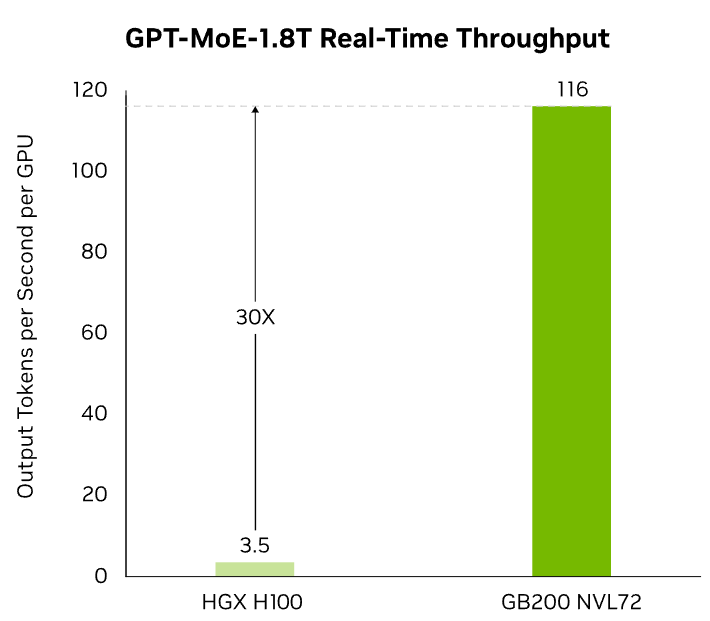
The NVIDIA GB200 NVL72 brings unprecedented speed to large language model performance, powered by its second-generation Transformer Engine with support for cutting-edge FP4 precision. Enhanced with fifth-generation NVIDIA NVLink™, this platform delivers up to 30× faster real-time inference for trillion-parameter models — making previously unattainable workloads a reality.
At the core are next-gen Tensor Cores featuring advanced microscaling formats that preserve accuracy while boosting throughput. Combined with a unified 72-GPU NVLink domain and liquid-cooled efficiency, the NVL72 overcomes traditional communication bottlenecks — enabling seamless compute performance at rack scale.
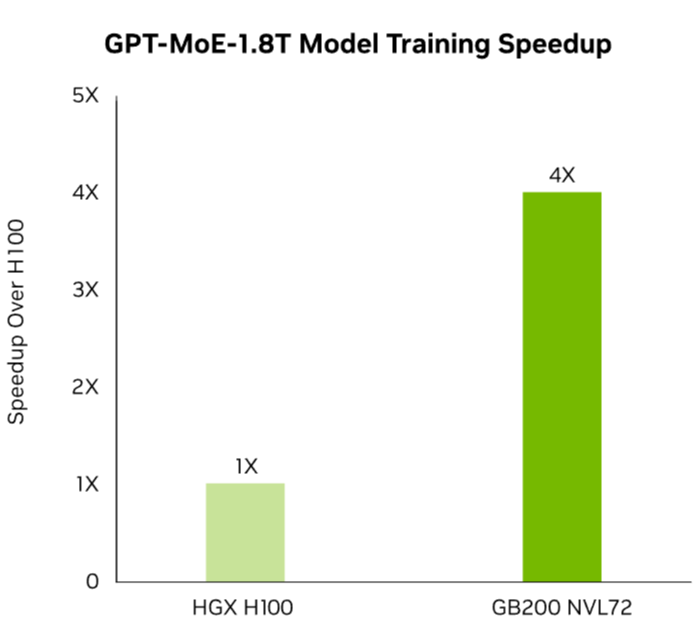
Engineered for the demands of next-generation AI, the NVIDIA GB200 NVL72 delivers up to 4× faster training for large language models, thanks to its second-generation Transformer Engine optimized for FP8 precision. This breakthrough in performance is supported by fifth-generation NVIDIA NVLink™, enabling 1.8 TB/s of high-speed GPU-to-GPU communication across the system.
Seamlessly integrated with NVIDIA InfiniBand networking and the high-performance NVIDIA Magnum IO™ software stack, the NVL72 empowers organizations to train trillion-parameter models with unmatched efficiency, scale, and speed — unlocking new frontiers in AI innovation.
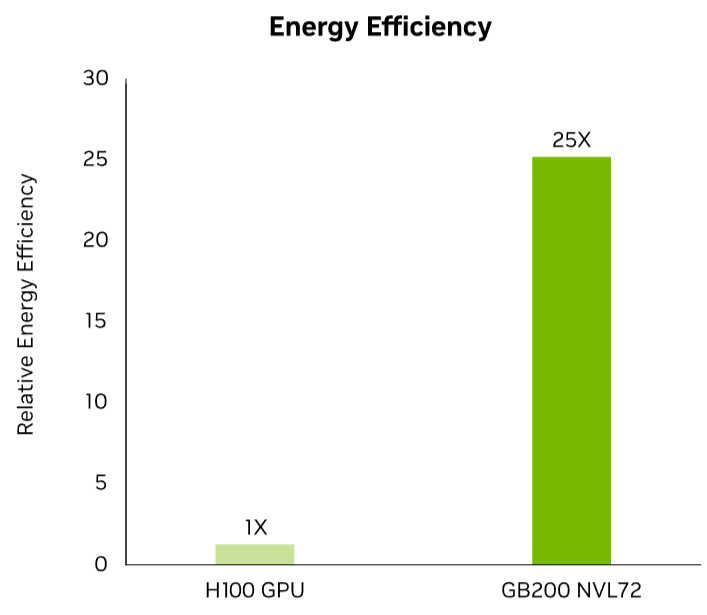
The liquid-cooled NVIDIA GB200 NVL72 sets a new benchmark for sustainable AI infrastructure. By dramatically increasing compute density while minimizing energy use, NVL72 systems enable data centers to achieve more with less — less power, less space, and less environmental impact.
With its advanced cooling architecture and expansive NVLink™ domain, the GB200 NVL72 ensures low-latency, high-bandwidth GPU communication across all 72 GPUs in a single rack. Compared to traditional air-cooled NVIDIA H100 systems, it delivers up to 25× more performance at the same power draw — all while significantly reducing water usage. It’s the smarter path forward for organizations scaling AI with sustainability in mind.
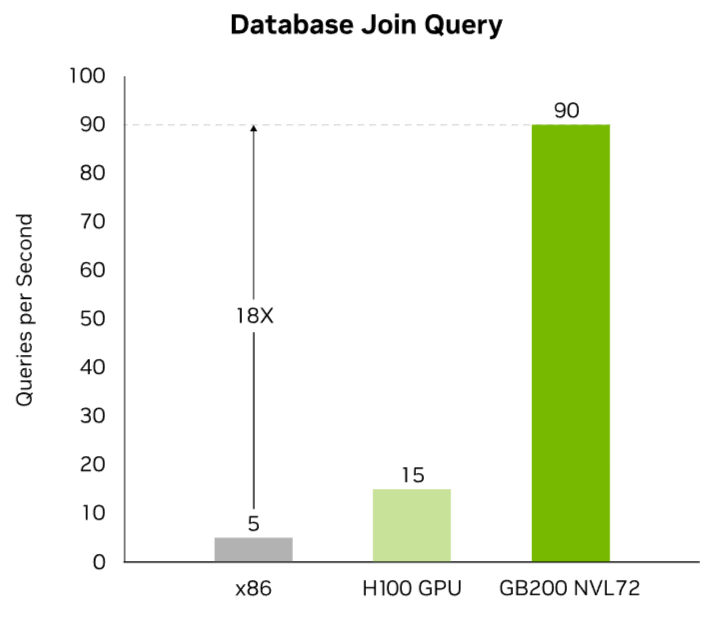
Enterprise databases demand extreme throughput to power real-time analytics and business-critical decision-making. The NVIDIA GB200 leverages the full strength of the Blackwell architecture — including high-bandwidth memory, NVLink-C2C interconnects, and built-in decompression engines — to dramatically accelerate data handling and query performance.
By optimizing database operations directly on the GPU, the GB200 delivers up to 18× faster query execution compared to traditional CPU-based systems, while improving total cost of ownership by up to 5×. Whether you’re processing massive datasets or supporting high-volume transactions, GB200 provides the scalable performance today’s data-driven enterprises require.
Technological Breakthroughs
A powerful convergence of next-generation architecture, energy-efficient CPUs, ultra-fast interconnects, and high-performance networking — all purpose-built to drive the future of AI at scale.
The NVIDIA Blackwell architecture represents a generational leap in accelerated computing, delivering industry-leading performance, efficiency, and scalability. Purpose-built for today’s largest AI and HPC workloads, Blackwell enables real-time inference, trillion-parameter training, and breakthrough compute density — all in a single architecture.
Engineered for modern data centers, the NVIDIA Grace CPU is optimized for AI, cloud, and high-performance computing applications. With exceptional memory bandwidth and up to 2× the energy efficiency of conventional server processors, Grace delivers the performance and sustainability enterprises need to stay competitive.
To power exascale computing and multi-trillion-parameter AI models, high-speed interconnects are critical. NVIDIA’s fifth-generation NVLink delivers seamless GPU-to-GPU communication at rack scale, creating a unified memory space and enabling performance previously only imagined.
As the foundation for scalable, distributed AI, NVIDIA networking solutions — including Quantum-X800 InfiniBand, Spectrum™-X800 Ethernet, and BlueField®-3 DPUs — provide the bandwidth, latency optimization, and intelligence required to orchestrate thousands of GPUs. From generative AI to HPC workloads, these technologies ensure your infrastructure operates with maximum efficiency and agility.

Unifying CPU and GPU Innovation—Next-Level Bandwidth and Performance for AI and HPC
The NVIDIA Grace Blackwell Superchip is a revolutionary compute engine purpose-built to tackle the most demanding AI and HPC workloads. Featuring a tightly coupled Grace CPU and Blackwell GPU connected via a 900 GB/s NVIDIA NVLink® Chip-2-Chip interface, the superchip delivers record-breaking performance with massive memory bandwidth and a shared memory model that simplifies complex data workflows. Designed for training trillion-parameter models, scientific simulations, and real-time inference at scale, the Grace Blackwell architecture empowers developers and researchers to push the boundaries of what’s computationally possible.
AI Supercomputing at Your Desk—Compact Power for Next-Generation Development
The NVIDIA DGX™ Spark is a groundbreaking desktop AI supercomputer designed to bring data center–level performance to individual developers, researchers, and data scientists. Powered by the NVIDIA GB10 Grace Blackwell Superchip, it combines a 20-core Arm CPU with a Blackwell GPU, delivering up to 1,000 AI TOPS of performance. With 128GB of unified LPDDR5x memory and up to 4TB of NVMe SSD storage, DGX Spark enables seamless development, fine-tuning, and inference of large AI models—supporting up to 200 billion parameters—right from your workspace.
Its compact form factor, measuring just 150mm x 150mm x 50.5mm, and energy-efficient 170W power consumption make it ideal for environments where space and power are at a premium. Equipped with a ConnectX-7 SmartNIC, DGX Spark supports high-speed networking, including 10GbE and 200GbE RDMA clustering, facilitating scalable AI workloads and collaboration. Whether you’re prototyping the next breakthrough in generative AI or deploying complex models, DGX Spark delivers the performance and flexibility needed to accelerate innovation at every stage.
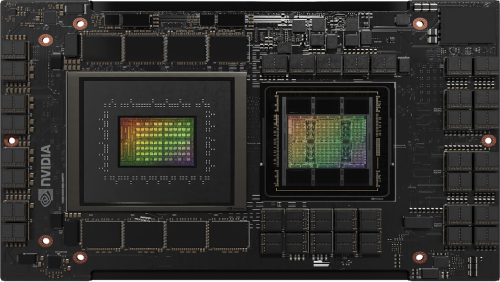
Higher Performance and Faster Memory—Massive Bandwidth for Compute Efficiency
The NVIDIA GH200 Grace Hopper Superchip is a breakthrough accelerated CPU designed from the ground up for giant-scale AI and high-performance computing (HPC) applications. The superchip delivers up to 10X higher performance for applications running terabytes of data, enabling scientists and researchers to reach unprecedented solutions for the world’s most complex problems.

The NVIDIA GH200 Grace Hopper Superchip combines the NVIDIA Grace and Hopper architectures using NVIDIA® NVLink®-C2C to deliver a CPU+GPU coherent memory model for accelerated AI and HPC applications.

Designed to Meet the Performance and Efficiency Needs of Today’s AI Data Centers
NVIDIA Grace is designed for a new type of data center—one that processes mountains of data to produce intelligence. These data centers run diverse workloads, from AI to high-performance computing (HPC) to data analytics, digital twins, and hyperscale cloud applications. NVIDIA Grace delivers 2X the performance per watt, 2X the packaging density, and the highest memory bandwidth compared to today’s DIMM-based servers to meet the most demanding needs of the data center.

The NVIDIA Grace CPU Superchip uses the NVIDIA® NVLink®-C2C technology to deliver 144 Arm® Neoverse V2 cores and 1 terabyte per second (TB/s) of memory bandwidth.
Runs all NVIDIA software stacks and platforms, including NVIDIA RTX, NVIDIA HPC SDK, NVIDIA AI, and NVIDIA Omniverse.
Optimized for AI
Our Value
As a leading HPC provider, Aspen Systems offers a standardized build and package selection that follows HPC best practices. However, unlike some other HPC vendors, we also provide you the opportunity to customize your cluster hardware and software with options and capabilities tuned to your specific needs and your environment. This is a more complex process than simply providing you a “canned” cluster, which might or might not best fit your needs. Many customers value us for our flexibility and engineering expertise, coming back again and again for upgrades to existing clusters or new clusters which mirror their current optimized solutions. Other customers value our standard cluster configuration to serve their HPC computing needs and purchase that option from us repeatedly. Call an Aspen Systems sales engineer today if you wish to procure a custom-built cluster built to your specifications.
Aspen Systems typically ships clusters to our customers as complete turn-key solutions, including full remote testing by you before the cluster is shipped. All a customer will need to do is unpack the racks, roll them into place, connect power and networking, and begin computing. Of course, our involvement doesn’t end when the system is delivered.
With decades of experience in the high-performance computing industry, Aspen Systems is uniquely qualified to provide unparalleled systems, infrastructure, and management support tailored to your unique needs. Built to the highest quality, customized to your needs, and fully integrated, our clusters provide many years of trouble-free computing for customers all over the world. We can handle all aspects of your HPC needs, including facility design or upgrades, supplemental cooling, power management, remote access solutions, software optimization, and many additional managed services.
Aspen Systems offers industry-leading support options. Our Standard Service Package is free of charge to every customer. We offer additional support packages, such as our future-proofing Flex Service or our fully managed Total Service package, along with many additional Add-on services! With our On-site services, we can come to you to fully integrate your new cluster into your existing infrastructure or perform other upgrades and changes you require. We also offer standard and custom Training packages for your administrators and your end-users or even informal customized, one-on-one assistance.


The most powerful end-to-end AI supercomputing platform.
AI, complex simulations, and massive datasets require multiple GPUs with extremely fast interconnections and a fully accelerated software stack. The NVIDIA HGX AI supercomputing platform brings together the full power of NVIDIA GPUs, NVLink®, NVIDIA networking, and fully optimized AI and high-performance computing (HPC) software stacks to provide the highest application performance and drive the fastest time to insights.
NVIDIA HGX H100 combines H100 Tensor Core GPUs with high-speed interconnects to form the world’s most powerful servers. Configurations of up to eight GPUs deliver unprecedented acceleration, with up to 640 gigabytes (GB) of GPU memory and 24 terabytes per second (TB/s) of aggregate memory bandwidth. And a staggering 32 petaFLOPS of performance creates the world’s most powerful accelerated scale-up server platform for AI and HPC.
HGX H100 includes advanced networking options— at speeds up to 400 gigabits per second (Gb/s)—utilizing NVIDIA Quantum-2 InfiniBand and Spectrum-X Ethernet for the highest AI performance. HGX H100 also includes NVIDIA® BlueField®-3 data processing units (DPUs) to enable cloud networking, composable storage, zero-trust security, and GPU compute elasticity in hyperscale AI clouds.
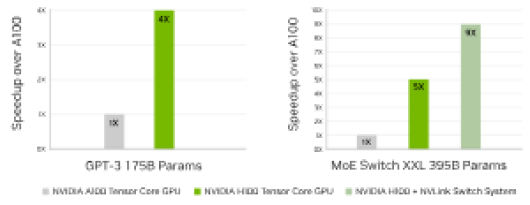
GPT-3 175B training NVIDIA A100 Tensor Core GPU cluster: NVIDIA Quantum InfiniBand network, H100 cluster: NVIDIA Quantum-2 InfiniBand network | Mixture of Experts (MoE) training transformer switch-XXL variant with 395B parameters on 1T token dataset, A100 cluster: NVIDIA Quantum InfiniBand network, H100 cluster: NVIDIA Quantum-2 InfiniBand network with NVLink Switch System where indicated. (Note: H100 systems offering NVLink NVSwitch System are not currently available.)
NVIDIA H100 GPUs feature the Transformer Engine, with FP8 precision, that provides up to 4X faster training over the prior GPU generation for large language models. The combination of fourth-generation NVIDIA NVLink, which offers 900GB/s of GPU-to-GPU interconnect, NVLink Switch System, which accelerates collective communication by every GPU across nodes, PCIe Gen5, and Magnum IO software delivers efficient scalability, from small enterprises to massive unified GPU clusters. These infrastructure advances, working in tandem with the NVIDIA AI Enterprise software suite, make HGX H100 the most powerful end-to-end AI and HPC data center platform.
Megatron chatbot inference with 530 billion parameters.
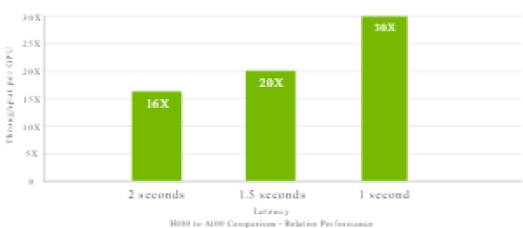
Inference on Megatron 530B parameter model chatbot for input sequence length = 128, output sequence length = 20 , A100 cluster: NVIDIA Quantum InfiniBand network; H100 cluster: NVIDIA Quantum-2 InfiniBand network for 2x HGX H100 configurations; 4x HGX A100 vs. 2x HGX H100 for 1 and 1.5 sec ; 2x HGX A100 vs. 1x HGX H100 for 2 sec.
NVIDIA H100 GPUs feature the Transformer Engine, with FP8 precision, that provides up to 4X faster training over the prior GPU generation for large language models. The combination of fourth-generation NVIDIA NVLink, which offers 900GB/s of GPU-to-GPU interconnect, NVLink Switch System, which accelerates collective communication by every GPU across nodes, PCIe Gen5, and Magnum IO software delivers efficient scalability, from small enterprises to massive unified GPU clusters. These infrastructure advances, working in tandem with the NVIDIA AI Enterprise software suite, make HGX H100 the most powerful end-to-end AI and HPC data center platform.
3D FFT (4K^3) throughput | HGX A100 cluster: NVIDIA Quantum InfiniBand network | H100 cluster: NVLink Switch System, NVIDIA Quantum-2 InfiniBand | genome sequencing (Smith-Waterman) | A100 | H100.
HGX H100 triples the floating-point operations per second (FLOPS) of double-precision Tensor Cores, delivering up to 535 teraFLOPS of FP64 computing for HPC in the 8-GPU configuration or 268 teraFLOPs in the 4-GPU configuration. AI-fused HPC applications can also leverage H100’s TF32 precision to achieve nearly 8,000 teraFLOPS of throughput for single-precision matrix-multiply operations with zero code changes.
H100 features DPX instructions that speed up dynamic programming algorithms—such as Smith-Waterman used in DNA sequence alignment and protein alignment for protein structure prediction—by 7X over NVIDIA Ampere architecture-based GPUs. By increasing the throughput of diagnostic functions like gene sequencing, H100 can enable every clinic to offer accurate, real-time disease diagnosis and precision medicine prescriptions.

Scalable data center infrastructure for high-performance AI and graphics.
From physically accurate digital twins to generative AI, training and inference, NVIDIA OVX systems deliver industry-leading graphics and compute performance to accelerate the next generation of AI-enabled workloads in the data center.
Built and sold by NVIDIA-Certified partners, each NVIDIA OVX system combines up to eight of the latest NVIDIA Ada Lovelace L40S GPUs with high-performance ConnectX and Bluefield networking technology to deliver accelerated performance at scale.
From Generative AI to virtualization, Nvidia’s OVX Systems are purpose-built to tackle your most demanding workloads.

Develop new services, insights, and original content.

Accelerate AI training and inference workloads.

Create and operate metaverse applications.

Power high-fidelity creative workflows with NVIDIA RTX graphics.
The most common plug/receptacle types you will encounter in North America are:
 Cooling
CoolingTo figure out which size unit is best for your cooling needs:
 SuperMicro
SuperMicro