
Custom AI Solutions Designed, Built, Deployed, and Supported
Unlock new insights, accelerate discovery, and drive innovation with Aspen Systems' turnkey AI solutions
Artificial Intelligence
Leverage the Power of AI to Generate new insight and accelerate the future.
Overview
Investing in AI is paramount for organizations seeking to elevate their capabilities and stay at the forefront of technological innovation. AI and HPC synergize effectively, as the computational demands of AI tasks often align with the strengths of HPC infrastructure. The parallel processing capabilities of HPC systems significantly accelerate the training and inference processes of complex AI models, enabling faster and more efficient analysis of large datasets. This collaboration between HPC and AI enhances the development and deployment of sophisticated algorithms, facilitating breakthroughs in areas like scientific research, data analytics, and simulations. By harnessing the power of AI, HPC companies can optimize their workflows, improve the accuracy of simulations, and drive advancements in fields such as weather forecasting, materials science, and drug discovery. In essence, the integration of AI into HPC not only unlocks new opportunities for innovation but also enhances performance and competitiveness in a rapidly evolving technological landscape.
Aspen Systems AI Solutions
Aspen Systems Inc. accelerates your future with fully custom, bleeding-edge, turnkey AI solutions.
Aspen Systems Inc. is you premier choice for AI solutions, giving you access to the state-of-the-art hardware, software, and expertise needed to drive innovation with AI. Our expert team of sales engineers understand the need to train and tune AI models faster, and the full stack implications that come along with it. Our expertise is where ambition meets reality, ensuring that no requirements – from storage, to networking, to cooling, and power consumption – are overlooked, allowing your models to continuously and autonomously train, adapt, and learn – at scale.
Our holistic approach to cluster design ensures that you have the networking, storage, and cooling needed to maximize the efficiency of these massive computing capacities. With our thorough, proprietary burn-in process, you will receive a thoroughly tested, turn-key AI solution, professionally installed (and supported), and ready to discover the unknown.
How can AI help push HPC Forward?
There are many similarities between HPC implementations and AI implementations in terms of architecture. The two processes typically process massive data sets of increasing size by using high levels of compute, storage, and bandwidth, as well as high-bandwidth fabrics. HPC’s big, multidimensional data sets are perfectly suited for deep learning.
Types of AI
Unlock the Power of AI with Aspen Systems Solutions
Aspen Systems delivers turnkey AI infrastructure designed to accelerate training, inference, machine learning, and visual computing workloads with expert integration, optimization, and support.

Generative AI

Deep Learning

Computer Vision
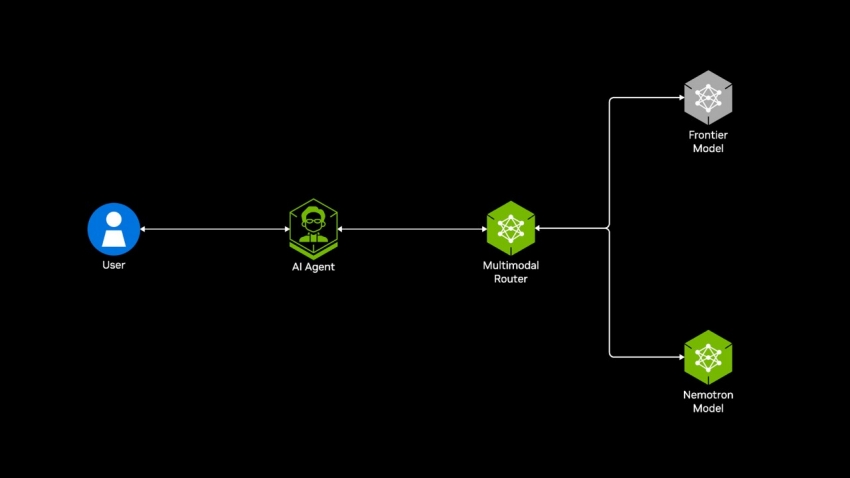
Frontier Model
Foundation Model
Types of AI
Machine Learning
Machine learning is a branch of artificial intelligence that enables computers to learn patterns from data and improve their performance over time without being explicitly programmed.
Deep Learning
Deep learning is a branch of machine learning that uses multi-layered neural networks to automatically learn complex patterns from data, powering technologies like image recognition, speech recognition, and natural language processing.
Generative AI
Generative AI is a branch of artificial intelligence that creates new content—such as text, images, audio, and designs—by learning patterns from existing data.
Key Processes: Training Vs. Inference
AI Training
AI training is a crucial process wherein artificial intelligence models, such as neural networks, learn and improve their performance through exposure to vast datasets. During training, the model adjusts its parameters based on input data, iteratively refining its ability to recognize patterns, make predictions, or perform specific tasks. This iterative learning process is fundamental to enhancing the capabilities of AI systems across diverse applications, ranging from natural language processing to image recognition.
AI Inference
AI inference is the phase where a trained artificial intelligence model applies its learned knowledge to make predictions or decisions based on new, unseen data. Unlike the training phase, which focuses on optimizing model parameters using extensive datasets, inference involves efficiently executing the model to provide real-time insights or responses. This deployment stage is vital for integrating AI into practical applications, enabling systems to utilize their learned knowledge to analyze and interpret information in a variety of domains, from autonomous vehicles to healthcare diagnostics.
Key Processes: Training Vs. Inference
AI Training
AI training is a crucial process wherein artificial intelligence models, such as neural networks, learn and improve their performance through exposure to vast datasets. During training, the model adjusts its parameters based on input data, iteratively refining its ability to recognize patterns, make predictions, or perform specific tasks. This iterative learning process is fundamental to enhancing the capabilities of AI systems across diverse applications, ranging from natural language processing to image recognition.
AI Inference
AI inference is the phase where a trained artificial intelligence model applies its learned knowledge to make predictions or decisions based on new, unseen data. Unlike the training phase, which focuses on optimizing model parameters using extensive datasets, inference involves efficiently executing the model to provide real-time insights or responses. This deployment stage is vital for integrating AI into practical applications, enabling systems to utilize their learned knowledge to analyze and interpret information in a variety of domains, from autonomous vehicles to healthcare diagnostics.
Turn Key Solutions
We handle everything from design to deployment to ongoing support, so you always know who to call.
Design
Expert architecture and custom system design tailored to your workload and goals.
Integration
Precision integration of industry-leading compute, networking, storage, and software technologies.
Deploy
Seamless deployment and testing to deliver full performance from day one, every time.
Support
Responsive support and service to keep your systems running at peak performance, always.
GPU + APU Technology
Navigating AI Hardware
From training large language models to deploying AI inference at scale, modern AI applications require powerful, purpose-built hardware. Aspen Systems combines industry-leading components with the expertise of our preferred and elite technology partnerships to deliver optimized, turnkey AI solutions. Here are some of the leading hardware technologies built into our platforms.
NVIDIA B200 & B300
The latest NVIDIA B200 and B300 GPUs power the next generation of AI. Each B200 GPU has 180GB of memory and each GB300 GPU has 288GB of memory to support the largest models and perform tasks at blistering speeds with up to 14.4TB/s of aggregate bandwidth via NVLink to power your AI Factory. They achieve up to 144petaFLOPS of inference performance to go up to 3x training performance and 15x inferencing performance compared to the same number of H100 GPUs in a system.
NVIDIA H200
Tap into extreme performance, scalability, and security for every workload with the NVIDIA H200. The H200 comes in two form factors: SXM and PCIe. These GPUs provide double precision capabilities with over 30TFLOPS in FP64. Each GPU has 141GB of HBM3e memory and support NVLINK up to 900GB/s to fuel the acceleration of generative AI and large language models (LLMs) while advancing scientific computing for HPC workloads.
NVIDIA RTX Pro 6000 Blackwell
Packed with 96GB of GDDR7 memory and based on the Blackwell architecture, the RTX Pro 6000 Blackwell family combines AI compute with the highest bar of visual performance to allow every workload from agentic AI to 3D graphics and rendering to stand leaps and bounds above all others. The RTX Pro 6000 Blackwell comes in multiple models such as the Server Edition, Workstation Edition, and Max-Q Workstation Edition for not only the server environment, but local workstation environments as well.
AMD MI350X
The MI350X family is based on the latest 4th Gen AMD CDNA architecture for high-speed inferencing, training AI models, and performing HPC workloads such as modeling and data processing with exceptional efficiency. The OAM form factor has up to 288GB of HBM3E memory and the PCIe version has 144GB HBM3E memory to support extremely large models. The MI355X edges out the B200 in certain benchmarks such as Sparsity in AI inferencing to give your AI / ML workloads the greatest platform to operate on.
Intel Gaudi 3
With up to a 4x improvement to FP16 and 2x improvement to FP8 AI Compute compared to the previous Gaudi 2 accelerator, Gaudi 3 improves on not only AI performance, but the ease of developing AI models with Intel’s power tools and software to get your workloads started or ported over quickly and scale effortlessly. Gaudi 3 has up to 4.2TB/s of bi-directional bandwidth and 128GB of HBM2e memory per accelerator while still being a cost effective solution.
AI Storage
AI applications often require massive amounts of storage to support the large datasets used for training and running machine learning models. Below are some of the storage solutions that Aspen Systems integrates into our GPU-based AI and HPC platforms to deliver complete turnkey infrastructure optimized for performance, scalability, and reliability.
DDN A3I
AI Storage Integrated by Aspen Systems
DDN A3I delivers the performance, scalability, and reliability needed for AI training, inference, and data-intensive HPC workloads. Purpose-built for GPU-accelerated environments, A3I provides high-speed parallel access and flexible all-flash or hybrid architectures that scale from terabytes to tens of petabytes, enabling organizations to unlock the full potential of their data.
VAST
AI Storage Integrated by Aspen Systems
Aspen Systems delivers the VAST Data Platform as part of complete turnkey AI and HPC solutions. Designed for GPU-accelerated workloads, VAST provides the performance, scalability, and reliability needed for large-scale model training, real-time inference, and data-intensive applications—ensuring your infrastructure is ready for the next generation of AI and scientific computing.
Technology Partners
We Partner With Industry-Leading Vendors
Aspen Systems sources exclusively from select vendors, ensuring every component meets our standards for quality and performance.





Speak with one of our AI Sales Specialists about a custom AI solution
AI SOFTWARE STACK
Aspen Systems delivers turnkey AI solutions with expert installation, optimization, and support for PyTorch, TensorFlow, Keras, NVIDIA CUDA, and NVIDIA AI Enterprise, providing a production-ready platform for AI training and inference. Choose from Red Hat Enterprise Linux, Rocky Linux, Ubuntu, SUSE Linux, and other operating systems to create a solution tailored to your environment.

TensorFlow
TensorFlow, developed by Google, is an open-source machine learning library that has become a cornerstone in AI development. Known for its flexibility and scalability, TensorFlow supports a wide range of applications, from natural language processing to computer vision. Its high-level APIs, like Keras, make it accessible for both beginners and experts. TensorFlow's ecosystem includes TensorFlow Extended (TFX) for deploying production-ready machine learning pipelines.

PyTorch
PyTorch, maintained by Facebook's AI Research lab, has gained popularity for its dynamic computational graph, which provides flexibility in model development and debugging. PyTorch is often praised for its intuitive syntax and is commonly used in research settings. With the introduction of TorchScript, PyTorch also supports seamless deployment in production environments. The PyTorch ecosystem includes tools like torchvision and torchaudio for computer vision and audio processing tasks.

Keras
Keras, initially developed as a high-level API for TensorFlow, has evolved into an independent open-source library for building neural networks. Recognized for its user-friendly interface and modular design, Keras allows developers to quickly create and experiment with deep learning models. With TensorFlow 2.0, Keras has become the official high-level API for building models, demonstrating its widespread adoption and support.

NVIDIA AI Enterprise
NVIDIA AI Enterprise is an end-to-end, cloud-native software platform that accelerates data science pipelines and streamlines development and deployment of production-grade AI applications, including generative AI. Enterprises that run their businesses on AI rely on the security, support, and stability provided by NVIDIA AI Enterprise to ensure a smooth transition from pilot to production.

Nvidia CUDA
NVIDIA CUDA-X AI is a complete deep learning software stack for researchers and software developers to build high performance GPU-accelerated applications for conversational AI, recommendation systems and computer vision. CUDA-X AI libraries deliver world leading performance for both training and inference across industry benchmarks such as MLPerf.
AI SOFTWARE STACK
Aspen Systems delivers turnkey AI solutions with expert installation, optimization, and support for PyTorch, TensorFlow, Keras, NVIDIA CUDA, and NVIDIA AI Enterprise, providing a production-ready platform for AI training and inference. Choose from Red Hat Enterprise Linux, Rocky Linux, Ubuntu, SUSE Linux, and other operating systems to create a solution tailored to your environment.
Shop Now
Shop AI-Ready Servers
Explore our customizable AI server solutions through our online product configurator, or request a quote to connect with one of our sales specialists. Our team can help simplify the configuration process, recommend custom solutions, and provide a complimentary budgetary estimate tailored to your requirements.
 SuperMicro
SuperMicro SuperMicro
SuperMicro SuperMicro
SuperMicro SuperMicro
SuperMicro SuperMicro
SuperMicro Supermicro
Supermicro SuperMicro
SuperMicro SuperMicro
SuperMicroTrusted partnership by known organizations

Get a Quote for a Custom AI Solution
Request a Quote
Tell us about your requirements, and our experts will design a custom solution tailored to your needs. We’ll help you identify the right configuration and provide a complimentary budgetary estimate based on your performance goals and budget.
 Cooling
Cooling