ABOUT BEEGFS
BeeGFS is a hardware-independent POSIX parallel file system (a.k.a. Software-defined Parallel Storage) designed to optimize performance and to be easily used, installed, and managed. In addition to offering a self-supported Community Edition and a fully supported Enterprise Edition, BeeGFS is built on an Available Source development model (source code is public). The BeeGFS platform is designed to run in all performance-driven environments including HPC, AI, Deep Learning, Life Sciences, and Oil & Gas (to name a few).

Speak with One of Our System Engineers Today
HOW BEEGFS WORKS
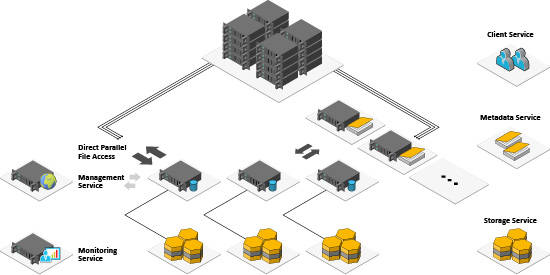
BeeGFS uses lightweight, high performance, user space daemon(s) that communicates over the arbitrated filesystem(s) ext4, zfs, xfs, Hadoop, etc. By doing so, users can enjoy maximum bandwidth and hardware performance, as well as delivering network wires speed to the applications. Native BeeGFS client and server components are available for Linux on x86, x86_64, AMD, ARM, and OpenPower CPU architectures.
In BeeGFS, the unique userspace architecture concept reduces metadata access latency (e.g., directory lookups) and distributes the metadata across multiple servers so that each metadata server stores a portion of the global file system namespace.
With the addition of more servers and disks, it is possible to scale the performance and capacity of the filesystem to meet your needs, from small clusters up to enterprise-class systems with thousands of nodes.
BEEGFS KEY FEATURES
BeeGFS transparently distributes user data across multiple servers. You can scale the performance and capacity of the file system up or down based on how many servers and disks you have in the system. It can scale from small clusters all the way up to enterprise-class systems with thousands of nodes.
Distributed File Contents and Metadata
With its user space architecture, BeeGFS is able to avoid architectural bottlenecks and locking situations in the cluster. This concept allows non-disruptive and linear scaling of metadata and storage.
Easy to Use
BeeGFS comes with graph-based Grafana dashboards, requires no kernel patches (user space daemons for the client and kernel modules for the servers), and can handle any number of clients and servers with no modification to the kernel.
Optimized for Highly Concurrent Access
In addition to having serious performance problems, NFS file systems can also corrupt data if a cluster of clients writes to a single shared file concurrently, which is a typical use case for cluster applications. In situations of high I/O loads or patterns, BeeGFS was specifically designed to deliver optimal robustness and performance.
HPC Technologies
The BeeGFS library is built upon highly efficient and scalable multithreaded core components that support native RDMA. Nodes within the File System can handle RDMA (InfiniBand, (Omni-Path), RoCE, and TCP/IP) network connections at the same time and automatically switch to a redundant connection path when one fails.
Client and Server on any Machine
BeeGFS does not require a specific enterprise Linux distribution or other special environment. Existing partitions can be formatted with any of the Linux file systems, e.g., XFS, ext4 or ZFS, which allows different use cases.
Speak with One of Our System Engineers Today
WHY USE BEEGFS?
A widely deployed alternative to other parallel filesystems, BeeGFS is used by thousands of sites worldwide to deliver fast access to storage systems of all types and sizes in a variety of performance-oriented environments including but not limited to HPC, AI, Deep Learning, Lifesciences, and Oil.
BeeGFS provides scalability & flexibility needed to run the most demanding HPC, AI, and business-critical applications, with a “state-of-the-art” userspace architecture that provides users with an ability to maintain any IO profile requirement without performance limitations.
With BeeGFS, customers get the opportunity to build HPC and AI infrastructures that can scale up and down from small sites to large clusters, relieving their hardware components of full bandwidth usage. The BeeGFS platform is capable of delivering faster results, allowing for new data analysis methods without requiring changes to workflows or apps.

Performance
Well-balanced from small to large files
Scalability
Increase file system performance and capacity, seamlessly and nondisruptive
Ease of Use
Easy to deploy and integrate with existing infrastructure
Robust
High availability design enabling continuous operations
 Cooling
Cooling