NVIDIA® GPUs
NVIDIA GPU – ONE PLATFORM. UNLIMITED DATA CENTER ACCELERATION.
 Researchers and engineers today must tackle increasingly complex challenges — from simulating physical phenomena to training state-of-the-art AI models and processing massive datasets for real-time insights. These workloads demand the power, scalability, and efficiency of modern accelerated computing infrastructure.
Researchers and engineers today must tackle increasingly complex challenges — from simulating physical phenomena to training state-of-the-art AI models and processing massive datasets for real-time insights. These workloads demand the power, scalability, and efficiency of modern accelerated computing infrastructure.
With the NVIDIA Hopper (H200) and newly introduced Blackwell architectures, the next generation of high-performance computing has arrived. Blackwell GPUs deliver breakthrough advancements in compute density, memory bandwidth, and power efficiency, enabling faster model training, more precise simulations, and dramatically improved throughput for AI inference and data analytics.
These architectures are purpose-built for the evolving demands of HPC and AI, offering flexible scalability from single-GPU deployments to multi-node clusters. With enhanced support for mixed-precision compute, advanced tensor core performance, and high-speed interconnects, Hopper and Blackwell empower data centers to meet the exponential growth in computational workloads.
As accelerated computing continues to evolve, NVIDIA’s platform is at the core of scientific innovation — helping organizations unlock new discoveries, accelerate research timelines, and turn massive volumes of data into meaningful insight.
OUR VALUE
DECADES OF SUCCESSFUL HPC DEPLOYMENTS
Architected For You
As a leading HPC provider, Aspen Systems offers a standardized build and package selection that follows HPC best practices. However, unlike some other HPC vendors, we also provide you the opportunity to customize your cluster hardware and software with options and capabilities tuned to your specific needs and your environment. This is a more complex process than simply providing you a “canned” cluster, which might or might not best fit your needs. Many customers value us for our flexibility and engineering expertise, coming back again and again for upgrades to existing clusters or new clusters which mirror their current optimized solutions. Other customers value our standard cluster configuration to serve their HPC computing needs and purchase that option from us repeatedly. Call an Aspen Systems sales engineer today if you wish to procure a custom-built cluster built to your specifications.
Solutions Ready To Go
Aspen Systems typically ships clusters to our customers as complete turn-key solutions, including full remote testing by you before the cluster is shipped. All a customer will need to do is unpack the racks, roll them into place, connect power and networking, and begin computing. Of course, our involvement doesn’t end when the system is delivered.
True Expertise
With decades of experience in the high-performance computing industry, Aspen Systems is uniquely qualified to provide unparalleled systems, infrastructure, and management support tailored to your unique needs. Built to the highest quality, customized to your needs, and fully integrated, our clusters provide many years of trouble-free computing for customers all over the world. We can handle all aspects of your HPC needs, including facility design or upgrades, supplemental cooling, power management, remote access solutions, software optimization, and many additional managed services.
Passionate Support, People Who Care
Aspen Systems offers industry-leading support options. Our Standard Service Package is free of charge to every customer. We offer additional support packages, such as our future-proofing Flex Service or our fully managed Total Service package, along with many additional Add-on services! With our On-site services, we can come to you to fully integrate your new cluster into your existing infrastructure or perform other upgrades and changes you require. We also offer standard and custom Training packages for your administrators and your end-users or even informal customized, one-on-one assistance.
Shop Now
Aspen Products Featuring the Nvidia GPU
 SuperMicro
SuperMicro SuperMicro
SuperMicro SuperMicro
SuperMicro SuperMicro
SuperMicro ASUS
ASUS ASUS
ASUSSpeak with One of Our System Engineers Today
Compare Nvidia GPUs
Select a GPU to Get Started
WHAT TYPE OF GPU ARE YOUR LOOKING FOR?

Data Center Double Precision & Compute GPUs
| Name | H200 (SXM) |
H200 (NVL) |
A800 |
|---|---|---|---|
| Appearance |  |
 |
 |
| Architecture | Hopper | Hopper | Ampere |
| FP64 | 34 TF | 34 TF | 9.7 TF |
| FP64 Tensor Core | 67 TF | 67 TF | |
| FP32 | 67 TF | 67 TF | 19.5 TF |
| Tensor Float 32 (TF32) | 156 TF | 312 TF* | 156 TF | 312 TF* | |
| BFLOAT16 Tensor Core | 1,979 TF | 1,979 TF | 624 TF |
| FP16 Tensor Core | |||
| INT8 Tensor Core | 3,958 TOPS | 3,958 TOPS | |
| GPU Memory | 141 GB | 141 GB | 40 GB |
| GPU Memory Bandwidth | 4.8 TB/s | 4.8 TB/s | 1.5 TB/s |
| TDP | Up to 700 W |
Up to 600 W | 240 W |
| Interconnect | NVLink: 900GB/s PCIe Gen5: 128GB/s |
NVLink: 900GB/s PCIe Gen5: 128GB/s |
NVLink: 400GB/s PCIe Gen4: 64GB/s |
Blackwell RTX Pro Series GPUs
| Name | 6000 Workstation | 6000 Server | 6000 Max Q | 5000 | 4500 | 4000 |
|---|---|---|---|---|---|---|
| Appearance |  |
 |
 |
 |
 |
 |
| Architecture | Blackwell | Blackwell | Blackwell | Blackwell | Blackwell | Blackwell |
| FP64 | 1.968 TF | 1.968 TF | 1.721 TF | 1,151 GF | 858.4 GF | 732.8 GF |
| FP32 | 126 TF | 120 TF | 110 TF | 73.69 TF | 54.94 TF | 46.9 TF |
| FP16 | 126 TF | 120 TF | 110 TF | 73.69 TF | 54.94 TF | 46.9 TF |
| AI TOPS | 4,000 TOPS | 3,511 TOPS | ||||
| RT Core Performance | 380 TFLOPS | 355 TFLOPS | 333 TFLOPS | |||
| GPU Memory | 96 GB GDDR7 w/ ECC |
96 GB GDDR7 w/ ECC |
96 GB GDDR7 w/ ECC |
48 GB GDDR7 w/ ECC |
32 GB GDDR7 w/ ECC |
24 GB GDDR7 w/ ECC |
| GPU Memory Bandwidth | 1,792 GB/s | 1,597 GB/s | 1,792 GB/s | 1,344 GB/s | 896 GB/s | 670 GB/s |
| TDP | 600 W | 600 W | 300 W | 300 W | 200 W | 140 W |
| Interconnect | PCIe Gen5: 128GB/s | PCIe Gen5: 128GB/s | PCIe Gen5: 128GB/s | PCIe Gen5: 128GB/s | PCIe Gen5: 128GB/s | PCIe Gen5: 128GB/s |
Data Center Ada Lovelace Single Precision GPUs
| Name | L40S | L4 |
|---|---|---|
| Appearance |  |
|
| Architecture | Ada Lovelace | Ada Lovelace |
| FP64 | ||
| FP32 | 91.6 TF | 30.3 TF |
| Tensor Float 32 (TF32) | 183 TF | 366 TF | 120 TF |
| BFLOAT16 Tensor Core | 362 TF | 733 TF | 242 TF |
| FP16 Tensor Core | ||
| INT8 Tensor Core | 733 TF | 1,466 TOPS | 485 TF |
| GPU Memory | 48 GB GDDR6 with ECC | 24 GB GDDR6 with ECC |
| GPU Memory Bandwidth | 864 GB/s | 300 GB/s |
| TDP | 350 W | 72 W |
| Interconnect | PCIe Gen4 64 GB/s (bidirectional) |
PCIe Gen4 64 GB/s (bidirectional) |
| Interconnect | NVLink: 900GB/s PCIe Gen5: 128GB/s |
NVLink: 400GB/s PCIe Gen4: 64GB/s |
Professional Ada Lovelace Series GPUs
| Name | RTX 6000 Ada | RTX 5000 Ada | RTX 4500 Ada | RTX 4000 Ada |
|---|---|---|---|---|
| Appearance |  |
 |
|
 |
| Architecture | Ada Lovelace | Ada Lovelace | Ada Lovelace | Ada Lovelace |
| FP64 | 1,423 GF | 1,020 GF | 619.2 GF | 299.5 GF |
| FP32 | 91 TF | 65.28 TF | 39.63 TF | 19.17 TF |
| BFLOAT16 Tensor Core | 91 TF | 65.28 TF | 39.63 TF | 19.17 TF |
| FP16 Tensor Core | ||||
| GPU Memory | 48GB GDDR6 | 32 GB GDDR6 | 24 GB GDDR6 | 20 GB GDDR6 |
| GPU Memory Bandwidth | 960 GB/s | 576 GB/s | 432 GB/s | 280 GB/s |
| TDP | 300 W | 250 W | 130 W | 70 W |
| Interconnect | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 |
Speak with One of Our System Engineers Today
NVIDIA GB300 NVL72
The Rack-Scale AI Supercomputer for the Trillion-Parameter Era
The NVIDIA GB300 NVL72 is a revolutionary rack-scale solution purpose-built to accelerate generative AI and large language model development. Featuring 72 NVIDIA Blackwell GPUs with fifth-generation NVLink and NVLink Switch System, the NVL72 delivers over 1.4 exaflops of AI performance and up to 30 TB of high-speed unified GPU memory — all within a single, liquid-cooled rack.
Engineered for massive-scale inference and training workloads, the GB300 NVL72 enables tight GPU-GPU communication with NVLink bandwidth 3X greater than PCIe Gen5, supporting new low-precision formats like FP4 and pushing AI throughput to unprecedented levels. Its integrated design simplifies deployment while maximizing power density and cooling efficiency.
From foundational AI research to real-time enterprise deployment, the NVIDIA GB300 NVL72 delivers the ultimate platform for organizations building the future of intelligence — with Aspen Systems ready to help you bring it online.
NVIDIA DGX™ B200
The Engine of Generative AI and Advanced Computing
The NVIDIA DGX™ B200 is the premier platform for building and deploying the most advanced AI models. Powered by eight NVIDIA Blackwell GPUs and fourth-generation NVLink, DGX B200 delivers breakthrough performance with up to 1.8 TB of unified GPU memory and lightning-fast bandwidth for training trillion-parameter models and running massive-scale inference.
Designed to handle the full spectrum of AI workloads — from foundation model development to real-time generative applications — DGX B200 features support for new precision formats like FP4 and accelerated AI math performance that’s up to 30X faster than previous generations. Integrated liquid cooling and a scalable architecture make DGX B200 the cornerstone of modern AI infrastructure.
Whether you’re developing frontier LLMs, building intelligent copilots, or powering autonomous systems, DGX B200 offers unmatched efficiency, density, and capability — all engineered to keep your data center at the cutting edge.
Revolutionary Performance
NVIDIA DGX™ B200 Platform Features
The NVIDIA DGX™ B200 redefines what’s possible across the full AI development lifecycle — from experimentation to enterprise-scale deployment. Featuring eight next-generation NVIDIA Blackwell GPUs and fifth-generation NVLink™ interconnects, the DGX B200 delivers up to 3× faster training speeds and up to 15× greater inference throughput compared to its predecessor. This makes it the ideal platform for tackling today’s most demanding AI challenges, including large language models, deep learning–powered recommendation engines, and advanced conversational AI. Whether you’re just starting your AI journey or scaling an established operation, DGX B200 delivers the horsepower and flexibility to accelerate innovation at every stage.

A Unified Platform for Every Stage of AI Development
Today’s enterprise AI workloads demand immense computational power — not just during training, but across the entire AI lifecycle. From initial model development and fine-tuning to high-throughput inference, the NVIDIA DGX™ B200 delivers the performance and scalability needed to streamline every phase. By equipping your team with a single, purpose-built platform, DGX B200 empowers developers to move faster, work smarter, and bring AI solutions to production with confidence.

Unmatched AI Performance, Engineered for What’s Next
Built on the transformative NVIDIA Blackwell architecture, the DGX™ B200 sets a new standard in accelerated computing — offering up to 3× the training power and 15× the inference speed of the previous DGX H100 generation. As the core of NVIDIA DGX BasePOD™ and DGX SuperPOD™ infrastructure, the DGX B200 delivers elite-level performance across the board, whether you’re training frontier models or scaling real-time AI applications in production.
A Trusted Standard for Scalable AI Infrastructure
The NVIDIA DGX™ B200 combines cutting-edge hardware with a fully integrated software stack to create a turnkey solution for enterprise AI. Featuring the complete suite of NVIDIA AI tools — including Base Command and NVIDIA AI Enterprise — the DGX B200 is ready to deploy out of the box. With robust support for third-party integrations and direct access to NVIDIA’s professional services, it provides a proven foundation for organizations looking to build, scale, and sustain high-performance AI initiatives with confidence.
Performance
Next-Level AI Performance Starts with DGX™ B200
Unlock unprecedented speed and scalability with the NVIDIA DGX™ B200 — the next evolution in enterprise AI computing. Designed to power tomorrow’s breakthroughs, DGX B200 delivers cutting-edge performance for training, inference, and deployment, all within a unified, ready-to-scale platform.
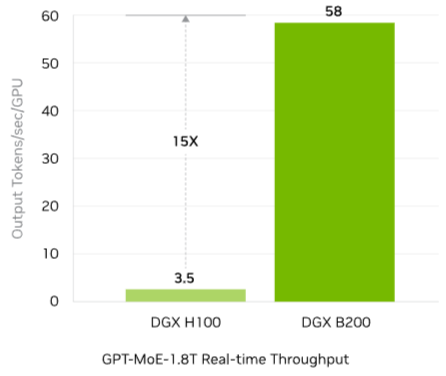
Real Time Large Language Model Inference
Projected performance subject to change. Token-to-token latency (TTL) = 50ms real time, first token latency (FTL) = 5s, input sequence length = 32,768, output sequence length = 1,028, 8x eight-way NVIDIA DGX H100 GPUs air-cooled vs. 1x eight-way NVIDIA DGX B200 air-cooled, per GPU performance comparison .
Supercharged AI Training Performance
Projected performance subject to change. 32,768 GPU scale, 4,096x eight-way NVIDIA DGX H100 air-cooled cluster: 400G IB network, 4,096x 8-way NVIDIA DGX B200 air-cooled cluster: 400G IB network.
Nvidia Blackwell Architecture
NVIDIA Blackwell Redefines Accelerated Computing
The NVIDIA Blackwell architecture represents a significant leap in accelerated computing, engineered to meet the demands of large-scale AI and high-performance computing (HPC) workloads. Featuring a dual-die design with 208 billion transistors, Blackwell GPUs are built using TSMC’s 4NP process and interconnected via a 10 TB/s NVLink-HBI interface, enabling them to function as a unified accelerator. The architecture introduces fifth-generation Tensor Cores with support for sub-8-bit data types, including FP4, enhancing efficiency and throughput for AI inference and training. Additionally, Blackwell’s second-generation Transformer Engine supports new microscaling formats like MXFP4 and MXFP6, further optimizing performance for large language models and AI applications. These advancements position Blackwell as a cornerstone for next-generation AI factories and HPC systems
Redefining What’s Possible
Blackwell Architecture Features
The NVIDIA Blackwell architecture sets a new benchmark for performance and scalability in AI and HPC environments. Designed to meet the growing demands of generative AI and large-scale compute workloads, Blackwell builds on years of innovation to deliver unmatched efficiency, throughput, and deployment flexibility. At Aspen Systems, we integrate Blackwell-based solutions to help our customers unlock faster insights, train larger models, and break through the limits of conventional computing.

Unmatched Multi-GPU Scaling with NVLink and NVLink Switch
Scaling trillion-parameter AI models and exascale HPC workloads requires more than raw GPU power—it demands ultra-fast, efficient communication across every GPU in a cluster. NVIDIA’s fifth-generation NVLink interconnect enables just that, scaling seamlessly across up to 576 GPUs to support the most compute-intensive AI applications on the planet.
At the core of this architecture is the NVIDIA NVLink Switch Chip, capable of delivering 130 TB/s of total bandwidth within a 72-GPU NVLink domain (NVL72). With support for NVIDIA SHARP™ and FP8 precision, the switch boosts reduction operations and improves bandwidth efficiency by 4x over traditional designs. And thanks to its 1.8 TB/s interconnect speed, NVLink can extend across multiple servers—enabling tightly coupled multi-GPU systems that scale linearly with workload demands. At Aspen Systems, we design and deliver NVLink-powered clusters that let you push your AI and HPC initiatives further, faster, and at full scale.

Next-Generation Performance with Blackwell AI Superchips
NVIDIA’s Blackwell GPUs introduce a new era of AI acceleration, featuring a dual-die design that brings together 208 billion transistors using a custom TSMC 4NP process. Each unit connects the dies with a blazing-fast 10 TB/s chip-to-chip link, allowing them to operate as a unified, high-throughput GPU. Aspen Systems integrates this cutting-edge architecture into purpose-built solutions that push the boundaries of AI model training, scientific workloads, and enterprise HPC.
Next-Gen Transformer Engine for Large-Scale AI
Built into the NVIDIA Blackwell architecture, the second-generation Transformer Engine delivers powerful acceleration for training and inferencing large language models (LLMs) and Mixture-of-Experts (MoE) architectures. Leveraging Blackwell’s advanced Tensor Core design alongside innovations in frameworks like TensorRT-LLM and NeMo, this engine introduces new microscaling formats for efficient precision handling without sacrificing accuracy.
The enhanced Ultra Tensor Cores offer 2x faster attention-layer processing and 1.5x greater AI compute throughput compared to previous generations. With micro-tensor scaling and FP4 support, Blackwell enables significantly larger model sizes within the same memory footprint—delivering faster results, lower energy costs, and greater capacity for next-gen AI development. Aspen Systems integrates this architecture into turnkey solutions designed for cutting-edge AI research and enterprise-scale inference.

Confidential AI at Scale
The NVIDIA Blackwell architecture introduces industry-first capabilities in confidential computing for GPUs—enabling organizations to protect sensitive data, proprietary AI models, and workloads without sacrificing performance. Featuring hardware-level security through NVIDIA Confidential Computing, Blackwell allows for secure model training, inference, and federated learning—even for the largest AI models.
As the first GPU to support TEE-I/O (Trusted Execution Environment for I/O), Blackwell enables secure communication with TEE-enabled hosts and inline data protection over NVIDIA NVLink. Remarkably, this level of encryption delivers throughput performance nearly identical to unencrypted workflows. At Aspen Systems, we deliver Blackwell-powered solutions that give enterprises peace of mind and performance in equal measure—ensuring your data and AI assets remain protected in every phase of deployment.
Accelerated Data Analytics with Hardware Decompression
Traditionally, data-intensive workloads like analytics and database queries have leaned heavily on CPUs—but the NVIDIA Blackwell architecture changes the equation. With a built-in decompression engine and high-bandwidth access to system memory via NVIDIA Grace CPUs, Blackwell delivers end-to-end acceleration for modern data science workflows.
Leveraging 900 GB/s of bidirectional bandwidth over the Grace high-speed interconnect, Blackwell offloads decompression tasks and speeds up query execution across platforms like Apache Spark. With native support for formats such as LZ4, Snappy, and Deflate, this architecture enables faster time-to-insight, reduced compute costs, and dramatically improved performance across large-scale analytics pipelines. Aspen Systems integrates Blackwell solutions that turn your data infrastructure into a high-throughput engine for real-time decision-making.

Built-In Resilience with Blackwell’s RAS Engine
To keep mission-critical AI and HPC systems running at peak efficiency, NVIDIA Blackwell introduces a dedicated Reliability, Availability, and Serviceability (RAS) Engine. This intelligent hardware feature enables proactive fault detection and real-time system health monitoring to prevent downtime before it happens.
Using AI-driven telemetry, the RAS engine continuously analyzes thousands of hardware and software signals to anticipate failures, streamline diagnostics, and support predictive maintenance. By pinpointing potential issues early and providing detailed insights for remediation, Blackwell helps reduce service interruptions, lower operating costs, and extend the lifecycle of your compute infrastructure. Aspen Systems delivers Blackwell-powered platforms built for performance—and built to last.
NVIDIA HGX™ platform
The Foundation of Accelerated AI and HPC
The NVIDIA HGX™ platform delivers unmatched performance and scalability for today’s most demanding AI and high-performance computing workloads. Built around NVIDIA’s latest Tensor Core GPUs — including Hopper and Blackwell — HGX enables ultra-fast multi-GPU communication via NVLink and NVSwitch, providing up to 900 GB/s of bandwidth and a unified memory space for massive AI models and large-scale simulations.
With support for advanced mixed-precision formats (FP8, FP16, BFLOAT16, TF32) and high-bandwidth HBM3e memory, HGX is optimized for training trillion-parameter LLMs, running real-time inference, and accelerating complex scientific research. From generative AI to seismic imaging, HGX powers the AI data center with the performance, efficiency, and flexibility needed to stay ahead.
Enhanced Performance
NVIDIA Hopper™ Architecture Features
Powered by the NVIDIA Hopper™ architecture, the NVIDIA H200 is the first GPU to feature 141 gigabytes (GB) of HBM3e memory, delivering a staggering 4.8 terabytes per second (TB/s) in bandwidth. This represents almost double the capacity of the NVIDIA H100 Tensor Core GPU and 1.4 times the memory bandwidth. With its increased memory size and speed, the H200 accelerates the performance of generative AI and large language models (LLMs), while also driving advancements in HPC workloads. Additionally, it offers improved energy efficiency and a reduced total cost of ownership.

Unlock Insights With High-Performance LLM Inference
In the ever-evolving landscape of AI, businesses rely on LLMs to address a diverse range of inference needs. An AI inference accelerator must deliver the highest throughput at the lowest TCO when deployed at scale for a massive user base.
The H200 boosts inference speed by up to 2X compared to H100 GPUs when handling LLMs like Llama2.

Boost High-Performance Computing Efficiency
In high-performance computing (HPC), memory bandwidth plays a vital role by speeding up data transfers and minimizing bottlenecks during complex processes. For memory-heavy HPC tasks such as simulations, scientific research, and AI applications, the H200’s superior memory bandwidth allows for quicker access and manipulation of data. This results in up to 110X faster outcomes compared to traditional CPU-based systems.

Lower Energy Consumption and Total Cost of Ownership
The H200 sets a new standard for energy efficiency and total cost of ownership (TCO). Delivering exceptional performance within the same power envelope as the H100, this advanced technology enables AI data centers and supercomputing systems to achieve faster speeds while becoming more environmentally friendly. The result is a significant economic advantage, driving progress in both the AI and scientific sectors.

NVIDIA A800 GPU
The ultimate workstation development platform for data science and HPC.
Bring the power of a supercomputer to your workstation and accelerate end-to-end data science workflows with the NVIDIA A800 40GB Active GPU. Powered by the NVIDIA Ampere architecture, the A800 40GB Active delivers powerful compute, high-speed memory, and scalability, so data professionals can tackle their most challenging data science, AI, and HPC workloads.
Software Tools for GPU Computing
Tensorflow Artificial Intelligence Library
Tensorflow, developed by google, is an open source symbolic math library for high performance computation. It has quickly become an industry standard for artificial intelligence and machine learning applications, and is known for its flexibility, used in many scientific disciplines. It is based on the concept of a Tensor, which, as you may have guessed, is where the Volta Tensor Cores gets its name.

GPU Accelerated Libraries
There are a handful of GPU accelerated libraries that developers can use to speed up applications using GPUs. Many of them are NVIDIA CUDA libraries (such as cuBLAS and CUDA Math Library), but there are others such as IMSL Fortran libraries and HiPLAR (High Performance Linear Algebra in R). These libraries can be linked to replace standard libraries that are commonly used in non-GPU-Accelerated computing.
CUDA Development Toolkit
NVIDIA has created an entire toolkit devoted to computing on their CUDA-enabled GPUs. The CUDA toolkit, which includes the CUDA libraries, are the core of many GPU-Accelerated programs. CUDA is one of the most widely used toolkits in the GPGPU world today.

NVIDIA Deep Learning SDK
In today’s world, Deep Learning is becoming essential in many segments of the industry. For instance, Deep Learning is key in voice and image recognition where the machine must learn while gaining input. Writing algorithms for machines to learn from data is a difficult task, but NVIDIA has written a Deep Learning SDK to provide the tools necessary to help design code to run on GPUs.
OpenACC Parallel Programming Model
OpenACC is a user-driven directive-based performance-portable parallel programming model. It is designed for scientists and engineers interested in porting their codes to a wide-variety of heterogeneous HPC hardware platforms and architectures with significantly less programming effort than required with a low-level model. . The OpenACC Directives can be a powerful tool in porting a user’s application to run on GPU servers. There are two key features to OpenACC: easy of use and portability. Applications that use OpenACC can not only run on NVIDIA GPUs, but it can run on other GPUs, X86 CPUs & POWER CPUs, as well.
 Cooling
Cooling